실습 1 : 최근 5년 역대 관객순위 1 ~ 5위 영화 이미지 가져오기
import requests
from bs4 import BeautifulSoup
for year in range(2018, 2023):
url = "https://search.daum.net/search?w=tot&q={}%EB%85%84%EC%98%81%ED%99%94%EC%88%9C%EC%9C%84&DA=MOR&rtmaxcoll=MOR".format(year)
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")...tot&q={}%EB%85%84%EC....format(year)
2018년부터 2022년까지 총 5개의 url를 접근하기 위하여 for문을 사용한다.
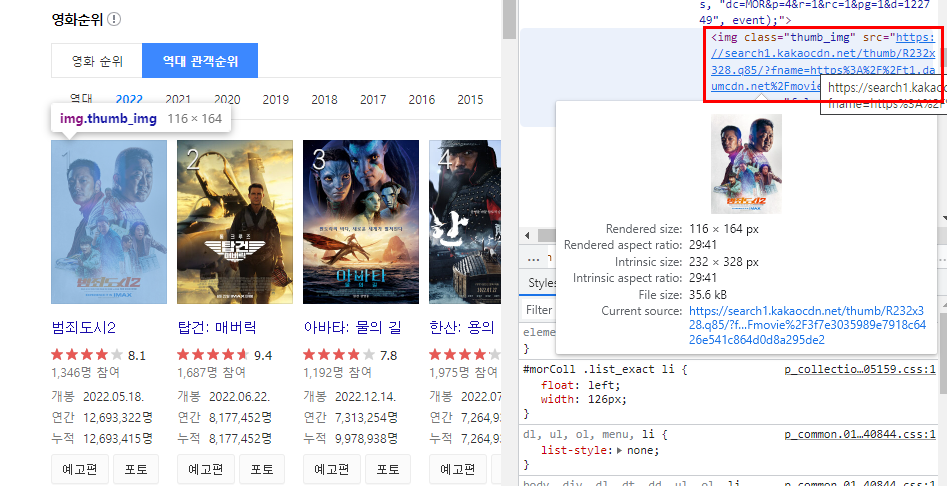
images = soup.find_all("img", attrs={"class": "thumb_img"})class 속성이 "thumb_img"인 모든 img 태그를 가져온다.
for idx, image in enumerate(images):
# print(image["src"])
image_url = image["src"] # 이미지의 url
if image_url.startswith("//"): # 만약 url이 //로 시작하는 경우 http:s를 붙여준다.
image_url = "https:" + image_url
img 태그의 소스("src") 정보를 가져온다. 이 소스 정보가 url을 의미한다.
가져온 이미지의 url이 "https:"가 아니라 "//"로 시작하는 경우 "https:"를 붙여준다.
image_res = requests.get(image_url) # 이미지를 가져오기 위하여 해당 이미지 url에 접속
image_res.raise_for_status()이미지의 url을 알았으므로 해당 이미지의 url에 다시 접속하고,
웹페이지가 정상인지 확인한다.
with open("movie_{}_{}.jpg".format(year, idx+1), "wb") as f: # 이미지를 바이너리로 저장
f.write(image_res.content) # 이미지(content) 쓰기이미지를 저장할 때는 바이너리로 저장하기 위해서 "wb"를 사용하고,
Write할 때는 Response 값의 Content를 바로 저장하면 이미지가 저장된다.
if idx >= 4: # 역대 관객 순위 1~5위만 가져오기
break역대 관객 순위 1~5위만 가져오기 위해서 index가 5이상이 되면 for문을 탈출한다.
전체 코드
import requests
from bs4 import BeautifulSoup
for year in range(2018, 2023):
url = "https://search.daum.net/search?w=tot&q={}%EB%85%84%EC%98%81%ED%99%94%EC%88%9C%EC%9C%84&DA=MOR&rtmaxcoll=MOR".format(year)
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
images = soup.find_all("img", attrs={"class": "thumb_img"})
for idx, image in enumerate(images):
# print(image["src"])
image_url = image["src"] # 이미지의 url
if image_url.startswith("//"): # 만약 url이 //로 시작하는 경우 http:s를 붙여준다.
image_url = "https:" + image_url
#print(image_url)
image_res = requests.get(image_url) # 이미지를 가져오기 위하여 해당 이미지 url에 접속
image_res.raise_for_status()
with open("movie_{}_{}.jpg".format(year, idx+1), "wb") as f: # 이미지를 바이너리로 저장
f.write(image_res.content) # 이미지(content) 쓰기
if idx >= 4: # 역대 관객 순위 1~5위만 가져오기
break
결과

이미지를 잘 가져왔다.
'Software > Python' 카테고리의 다른 글
| [웹스크래핑] Selenium(셀레니움) 셋업 (0) | 2023.01.30 |
|---|---|
| [웹스크래핑] BS4 활용 + CSV 기본 - 네이버 증권 (2) | 2023.01.26 |
| [웹스크래핑] Beautifulsoup4 활용 2 - 쿠팡 (0) | 2023.01.24 |
| [웹스크래핑] HTTP Method - Get vs. Post (0) | 2023.01.18 |
| [웹스크래핑] Beautifulsoup4 활용 1 - 네이버 웹툰 (0) | 2023.01.17 |




댓글