실습 1 : 쿠팡에서 노트북 제품 가져오기
import requests
import re
from bs4 import BeautifulSoup
url = "https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page=1&rocketAll=false&searchIndexingToken=1=6&backgroundColor="
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36", "Accept-Language": "ko-KR,ko;q=0.8,en-US;q=0.5,en;q=0.3"}
res = requests.get(url, headers=headers)
res.raise_for_status() # 웹페이지의 상태가 정상인지 확인
soup = BeautifulSoup(res.text, "lxml") # 가져온 HTML 문서를 파서를 통해 BeautifulSoup 객체로 만듦
쿠팡은 봇의 접근을 막기 때문에 User-Agent를 사용해줘야한다.
"Accept-Language": "ko-KR,ko;q=0.8,en-US;q=0.5,en;q=0.3"
또, headers 부분에 위 파라미터를 추가해줘야 정상적으로 작동한다.

items = soup.find_all("li", attrs={"class":re.compile("^search-product")}) # li 태그 중에서 class 옵션이 search-product로 시작하는 요소들만 가져온다.
li 태그에 class가 "search-product"로 시작하는 목록들만 가져온다. -> "^search-product"
print(items[0].find("div", attrs={"class":"name"}).get_text())가져온 목록들 중에서 첫번째(items[0]) 상품의 이름을 가져온다.
결과


여기서 주의해야할 점은 items[0]인데도 불구하고 항상 첫번째 상품만 가져오지 않는다는 것이다. 위의 상품을 가져온 것인데 5번째 상품을 가져왔다.

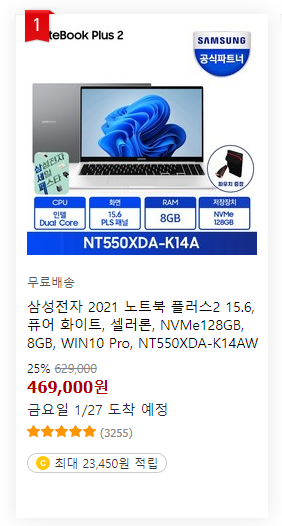
이번에는 첫 번째 상품을 정확히 가져왔다.
내가 접근한 url은 노트북을 검색한 후 첫 번째 페이지였지만, 세 번째 페이지의 상품을 가져오는 경우도 있었다. 정확한 이유는 모르겠지만, 스크래핑시 주의해야할 것 같다.
전체 코드
import requests
import re
from bs4 import BeautifulSoup
url = "https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page=1&rocketAll=false&searchIndexingToken=1=6&backgroundColor="
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36", "Accept-Language": "ko-KR,ko;q=0.8,en-US;q=0.5,en;q=0.3"}
res = requests.get(url, headers=headers)
res.raise_for_status() # 웹페이지의 상태가 정상인지 확인
soup = BeautifulSoup(res.text, "lxml") # 가져온 HTML 문서를 파서를 통해 BeautifulSoup 객체로 만듦
items = soup.find_all("li", attrs={"class":re.compile("^search-product")}) # li 태그 중에서 class 옵션이 search-product로 시작하는 요소들만 가져온다.
print(items[0].find("div", attrs={"class":"name"}).get_text())실습 2 : 쿠팡에서 노트북 제품 데이터 가져오기
import requests
import re
from bs4 import BeautifulSoup
url = "https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page=1&rocketAll=false&searchIndexingToken=1=6&backgroundColor="
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36", "Accept-Language": "ko-KR,ko;q=0.8,en-US;q=0.5,en;q=0.3"}
res = requests.get(url, headers=headers)
res.raise_for_status() # 웹페이지의 상태가 정상인지 확인
soup = BeautifulSoup(res.text, "lxml") # 가져온 HTML 문서를 파서를 통해 BeautifulSoup 객체로 만듦
items = soup.find_all("li", attrs={"class":re.compile("^search-product")}) # li 태그 중에서 class 옵션이 search-product로 시작하는 요소들만 가져온다.
실습 1과 동일하다.
제품명 가져오기

가격 가져오기

평점 가져오기

평점 수 가져오기
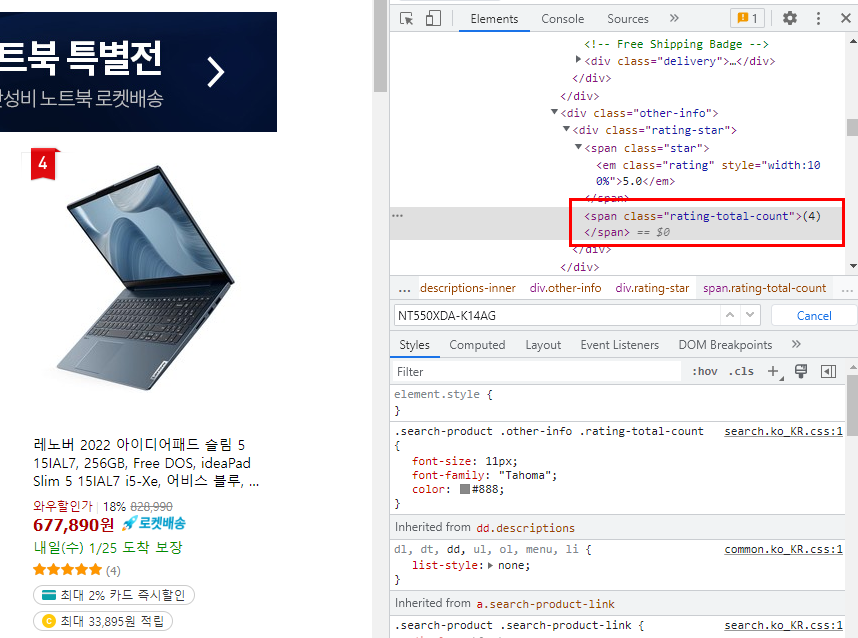
for item in items:
name = item.find("div", attrs={"class":"name"}).get_text() # 제품명
price = item.find("strong", attrs={"class":"price-value"}).get_text() # 가격
rate = item.find("em", attrs={"class":"rating"}) # 평점
if rate:
rate = rate.get_text()
else:
rate = "평점 없음"
rate_cnt = item.find("span", attrs={"class":"rating-total-count"}) # 평점 수
if rate_cnt:
rate_cnt = rate_cnt.get_text()
else:
rate_cnt = "평점 수 없음"
print(name, price, rate, rate_cnt)
각 태그의 옵션을 찾아서 해당되는 텍스트를 불러왔다.
평점과 평점 수는 없는 제품들은 "평점 없음"과 "평점 수 없음"을 출력하도록 했다.
결과

전체 코드
import requests
import re
from bs4 import BeautifulSoup
url = "https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page=1&rocketAll=false&searchIndexingToken=1=6&backgroundColor="
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36", "Accept-Language": "ko-KR,ko;q=0.8,en-US;q=0.5,en;q=0.3"}
res = requests.get(url, headers=headers)
res.raise_for_status() # 웹페이지의 상태가 정상인지 확인
soup = BeautifulSoup(res.text, "lxml") # 가져온 HTML 문서를 파서를 통해 BeautifulSoup 객체로 만듦
items = soup.find_all("li", attrs={"class":re.compile("^search-product")}) # li 태그 중에서 class 옵션이 search-product로 시작하는 요소들만 가져온다.
# print(items[0].find("div", attrs={"class":"name"}).get_text())
for item in items:
name = item.find("div", attrs={"class":"name"}).get_text() # 제품명
price = item.find("strong", attrs={"class":"price-value"}).get_text() # 가격
rate = item.find("em", attrs={"class":"rating"}) # 평점
if rate:
rate = rate.get_text()
else:
rate = "평점 없음"
rate_cnt = item.find("span", attrs={"class":"rating-total-count"}) # 평점 수
if rate_cnt:
rate_cnt = rate_cnt.get_text()
else:
rate_cnt = "평점 수 없음"
print(name, price, rate, rate_cnt)실습 3 : 쿠팡에서 조건에 맞는 노트북 제품 데이터 가져오기
조건 : 광고 제품 제외, 애플 제품 제외, 리뷰 100개 이상, 평점 4.5 이상


광고 제품 제외
# 광고 제품은 제외
ad_badge = item.find("span", attrs={"class": "ad-badge-text"})
if ad_badge:
print(" <광고 상품 제외합니다>")
continue광고 표시가 붙은 제품은 제외한다. 해당 제품의 광고가 있는 경우 continue를 하여 for문의 처음으로 돌아간다.
애플 제품 제외
# 애플 제품 제외
name = item.find("div", attrs={"class":"name"}).get_text() # 제품명
if "Apple" in name:
print(" <Apple 상품 제외합니다")
continue가져온 제품의 이름에 Apple이 들어가는 경우 제외한다.
리뷰 100개 이상, 평점 4.5 이상 제품만 가져오기
# 리뷰 100개 이상, 평점 4.5 이상 되는 것만 조회
rate = item.find("em", attrs={"class":"rating"}) # 평점
if rate:
rate = rate.get_text()
else:
#rate = "평점 없음"
print(" <평점 없는 상품 제외합니다>")
continue
rate_cnt = item.find("span", attrs={"class":"rating-total-count"}) # 평점 수
if rate_cnt:
rate_cnt = rate_cnt.get_text() # 예 : (26)
rate_cnt = rate_cnt[1:-1] # 괄호 없애기
# print("리뷰 수", rate_cnt)
else:
#rate_cnt = "평점 수 없음"
print(" <평점 수 없는 상품 제외합니다>")
continue
if float(rate) >= 4.5 and int(rate_cnt) >= 100:
print(name, price, rate, rate_cnt)전체 코드 : 1 ~ 5 페이지 스크래핑
import requests
import re
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36", "Accept-Language": "ko-KR,ko;q=0.8,en-US;q=0.5,en;q=0.3"}
for i in range(1, 6):
#print("페이지 :", i)
url = "https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page={}&rocketAll=false&searchIndexingToken=1=6&backgroundColor=".format(i)
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
items = soup.find_all("li", attrs={"class":re.compile("^search-product")})
# print(items[0].find("div", attrs={"class":"name"}).get_text())
for item in items:
# 광고 제품은 제외
ad_badge = item.find("span", attrs={"class":"ad-badge-text"})
if ad_badge:
#print(" <광고 상품 제외합니다>")
continue
name = item.find("div", attrs={"class":"name"}).get_text() # 제품명
# 애플 제품 제외
if "Apple" in name:
#print(" <Apple 상품 제외합니다")
continue
price = item.find("strong", attrs={"class":"price-value"}).get_text() # 가격
# 리뷰 100개 이상, 평점 4.5 이상 되는 것만 조회
rate = item.find("em", attrs={"class":"rating"}) # 평점
if rate:
rate = rate.get_text()
else:
#rate = "평점 없음"
#print(" <평점 없는 상품 제외합니다>")
continue
rate_cnt = item.find("span", attrs={"class":"rating-total-count"}) # 평점 수
if rate_cnt:
rate_cnt = rate_cnt.get_text()[1:-1] # 예 : (26), 괄호 없애기
else:
#rate_cnt = "평점 수 없음"
#print(" <평점 수 없는 상품 제외합니다>")
continue
link = item.find("a", attrs={"class":"search-product-link"})["href"]
if float(rate) >= 4.5 and int(rate_cnt) >= 100:
#print(name, price, rate, rate_cnt)
print(f"제품명 : {name}")
print(f"가격 : {price}")
print(f"평점 : {rate}점 ({rate_cnt})개")
print("바로가기 : {}".format("https://www.coupang.com/"+link))
print("-"*100)
1 ~ 5 페이지 반복하기
url = "https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page={}&rocketAll=false&searchIndexingToken=1=6&backgroundColor=".format(i)
rating=0&page={}&rocketAll
지금까지는 페이지 1에서만 스크래핑을 했다. 이번에는 for문을 사용하여 1~5 페이지를 스크래핑하는 방법이다. 페이지 번호를 i = 1 ~ 5까지 반복하여 1 ~ 5페이지 url에 접근했다. 그외 나머지는 실습 2와 같다.
링크 가져오기
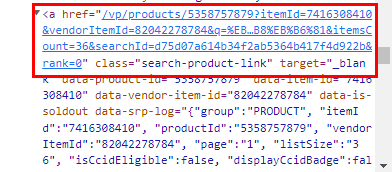
link = item.find("a", attrs={"class":"search-product-link"})["href"]print("바로가기 : {}".format("https://www.coupang.com/"+link))추가적으로, 해당 제품의 url에 접근할 수 있도록 링크 정보를 가져왔다.
해당 링크(a) 요소의 "href" 속성의 정보를 가져온다. 그 후에 "https://www.coupang.com/"(실제 쿠팡 주소)를 연결하여 해당 제품의 url 주소와 일치하게 만든다.
결과

'Software > Python' 카테고리의 다른 글
| [웹스크래핑] BS4 활용 + CSV 기본 - 네이버 증권 (2) | 2023.01.26 |
|---|---|
| [웹스크래핑] Beautifulsoup4 활용 3 - 다음 영화 (0) | 2023.01.24 |
| [웹스크래핑] HTTP Method - Get vs. Post (0) | 2023.01.18 |
| [웹스크래핑] Beautifulsoup4 활용 1 - 네이버 웹툰 (0) | 2023.01.17 |
| [웹스크래핑] Beautifulsoup4 기본 (0) | 2023.01.15 |




댓글