User Agent
무분별한 크롤링, 스크래핑을 막기 위해서 사람이 직접 웹페이지를 접속한 것이 아니라 로봇이나 프로그램이 접속하는 것을 차단하는 웹페이지들이 있다.
즉, Requests 라이브러리를 사용해서 접근하는 것을 막는 사이트들이 있다. 이러한 사이트들을 크롤링, 스크래핑을 하기 위해서 User Agent를 사용한다. 우리가 로봇이 아니라 사람임을 User Agent를 사용하여 웹페이지에게 알려줄 수 있다.
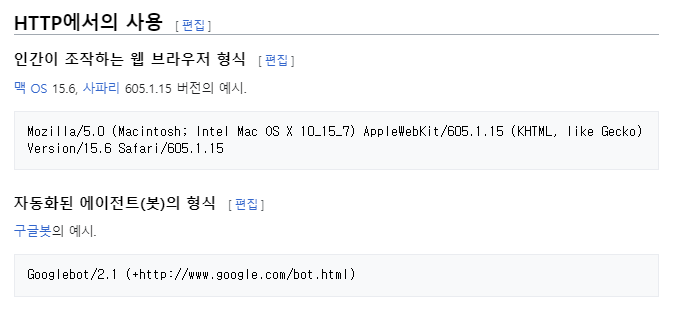
위의 이미지에서 인간이 조작하는 웹 브라우저 형식을 사용해야 웹페이지가 로봇으로 인식하지 않는다.
나의 User Agent 확인하기
https://www.whatismybrowser.com/detect/what-is-my-user-agent/
What is my user agent?
Every request your web browser makes includes your User Agent; find out what your browser is sending and what this identifies your system as.
www.whatismybrowser.com
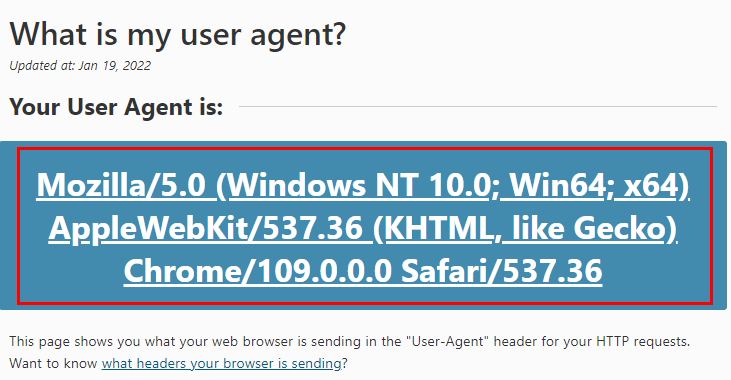
위 사이트에서 나의 User Agent를 확인할 수 있다.
전체 코드
import requests
url = "https://rimeestore.tistory.com/"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"}
res = requests.get(url, headers=headers) # url, user-agent
res.raise_for_status()
with open("rimee.html", "w", encoding="utf8") as f:
f.write(res.text)
User Agent를 사용해서 접근하면, 접근이 불가능한 웹페이지의 정보를 requests.get() 함수를 사용하여 가져올 수 있다.
참고
https://ko.wikipedia.org/wiki/%EC%82%AC%EC%9A%A9%EC%9E%90_%EC%97%90%EC%9D%B4%EC%A0%84%ED%8A%B8
'Software > Python' 카테고리의 다른 글
| [웹스크래핑] Beautifulsoup4 활용 1 - 네이버 웹툰 (0) | 2023.01.17 |
|---|---|
| [웹스크래핑] Beautifulsoup4 기본 (0) | 2023.01.15 |
| [웹스크래핑] 정규식(Regular Expression) (0) | 2023.01.15 |
| [웹스크래핑] Requests 라이브러리 기초 (0) | 2023.01.14 |
| [웹스크래핑] 웹크롤링 vs. 웹스크래핑 (0) | 2023.01.13 |


댓글